part2
제로초의 Node.js 교과서 섹션 2 요약
3.1 REPL 사용하기
REPL이라는 용어를 들어본 적이 있는가? 레플? 이라고 읽는 것 같다.
Read-Eval-Print-Loop의 사이클을 한 단어로 나타내는 용어인데, JavaScript와 Python같은 인터프리터 기반의 언어들에서는 일종의 대화형 코드 실행 인터페이스로서 제공하는 경우가 많다.
그게 가능한 이유는 그 언어들이 소스코드를 통째로 컴파일해야만 동작하는 것이 아니라 한줄 한줄 인터프리터가 읽어가면서 실행하는 방식으로 동작하기 때문이다.
Python에는 IDLE라는 인터페이스를 제공하고 있고, Node.js에서 REPL을 활용하고 싶으면 터미널을 열어서 node라는 명령어를 입력하면 된다.
그러면 마치 브라우저의 개발자 도구에 console 탭에서 볼 수 있는 것과 같은 코드 실행기가 실행된다.
Welcome to Node.js v20.8.1.
Type ".help" for more information.
>
3.2 JS 파일 실행하기
앞서 설명한 REPL은 아주 적은 양의 코드를 하나 하나 입력해보면서 실행 결과를 확인하는, 일종의 테스트 용도로 활용하는 데 적합하다.
수백 줄로 이루어진 거대한 코드 덩어리를 실행하는 데는 적합하지 않다는 이야기이다.
이런 경우에는 해당 코드를 .js 확장자를 가진 파일에 저장하고, 해당 파일을 node 명령어로 실행하는 방식이 적합하다.
node example.js
3.3 모듈로 만들기
Node.js는 모듈 시스템을 지원하기 때문에 단일 프로그램의 덩치가 너무 커지지 않도록 해당 프로그램을 여러개의 하위 모듈로 분리할 수 있다. 물론 그 모듈 또한 하나의 프로그램일 수 있고, 상위 모듈이 동작할 때 의존 관계에 있는 모듈들과 더불어 조립되어 상위 모듈을 동작시키게 된다.
3.3.1 CommonJS 모듈
CommonJS 모듈
CommonJS 모듈은 지금의 자바스크립트 표준인 ECMAScript가 나오기 이전에 쓰였던 방식으로, 여전히 많이 쓰이��고 있다.
모듈이 될 var.js와 모듈을 활용할 func.js, 그 둘을 활용할 index.js를 선언해보자.
// var.js
const odd = "홀수입니다.";
const even = "짝수입니다.";
module.exports = {
odd,
even,
};
// func.js
const { odd, even } = require("./var");
function isOdd(num) {
return num % 2 ? odd : even;
}
module.exports = isOdd;
// index.js
const { odd, even } = require("./var");
const isOdd = require("./func");
function isStrLengthOdd(str) {
return str.length % 2 ? odd : even;
}
console.log(isOdd(10));
console.log(isStrLengthOdd("hello"));
func.js는 var.js의 변수 정보를 활용하고 있고, index.js는 그 둘의 함수 또는 변수의 정보를 불러와 활용하고 있다.
여기서 주목할 것은 모듈이 "내보낼" 정보는 module.exports 객체에 할당하고 있다는 것과, 해당 모듈에서 내보내고 있는 정보를 "불러올" 때는 require() 함수를 사용하고 있다는 것이다.
여기서 module.exports 객체는 정보를 내보낼 때 활용되고 있지만, exports 객체도 같은 역할을 수행하고 있다. 이는 exports 객체가 module.exports 객체를 참조하고 있어, 결과적으로는 두 객체 모두 같은 대상을 참조하고 있기 때문이다.
단, exports 객체를 활용할 때 주의할 점이 있다.
- exports 객체에 직접 다른 값을 대입하면 module.exports 객체와의 참조 관계가 끊어져서 정보들이 제대로 내보내지지 않는다.
- 반드시 속성명과 속성값을 대입해야 한다.
그리고 exports 객체는 module.exports와 참조 관계에 있으므로, 같은 파일 내에서 둘 모두를 활용하는 것도 exports 객체로 내보내는 코드가 동작하지 않는 결과를 낳으므로 바람직하지 않다.
추가로 다음과 같은 특징도 기억하자.
- exports객체는 모듈 최상단에서 this 호출 시 바인딩 된다.
require() 함수는 객체로서의 속성을 몇 개 가지고 있는데, 이에 대해 알아보자.
// require.js
console.log("require는 최상단에 위치하지 않아도 됩니다.");
module.exports = "저를 찾아보세요.";
require("./var");
console.log("require.cache: ");
console.log(require.cache);
console.log("require.main: ");
console.log(require.main);
console.log(require.main === module);
console.log(require.main.filename);
위 파일을 실행하면 다음과 같은 결과를 얻을 수 있다. (실행 환경마다 다를 수 있다.)
require는 최상단에 위치하지 않아도 됩니다.
require.cache:
[Object: null prototype] {
'/Users/cheshier/Desktop/Learn/Node/Section 2/require.js': Module {
id: '.',
path: '/Users/cheshier/Desktop/Learn/Node/Section 2',
exports: '저를 찾아보세요.',
filename: '/Users/cheshier/Desktop/Learn/Node/Section 2/require.js',
loaded: false,
children: [ [Module] ],
paths: [
'/Users/cheshier/Desktop/Learn/Node/Section 2/node_modules',
'/Users/cheshier/Desktop/Learn/Node/node_modules',
'/Users/cheshier/Desktop/Learn/node_modules',
'/Users/cheshier/Desktop/node_modules',
'/Users/cheshier/node_modules',
'/Users/node_modules',
'/node_modules'
]
},
'/Users/cheshier/Desktop/Learn/Node/Section 2/var.js': Module {
id: '/Users/cheshier/Desktop/Learn/Node/Section 2/var.js',
path: '/Users/cheshier/Desktop/Learn/Node/Section 2',
exports: { odd: '홀수입니다.', even: '짝수입니다.' },
filename: '/Users/cheshier/Desktop/Learn/Node/Section 2/var.js',
loaded: true,
children: [],
paths: [
'/Users/cheshier/Desktop/Learn/Node/Section 2/node_modules',
'/Users/cheshier/Desktop/Learn/Node/node_modules',
'/Users/cheshier/Desktop/Learn/node_modules',
'/Users/cheshier/Desktop/node_modules',
'/Users/cheshier/node_modules',
'/Users/node_modules',
'/node_modules'
]
}
}
require.main:
Module {
id: '.',
path: '/Users/cheshier/Desktop/Learn/Node/Section 2',
exports: '저를 찾아보세요.',
filename: '/Users/cheshier/Desktop/Learn/Node/Section 2/require.js',
loaded: false,
children: [
Module {
id: '/Users/cheshier/Desktop/Learn/Node/Section 2/var.js',
path: '/Users/cheshier/Desktop/Learn/Node/Section 2',
exports: [Object],
filename: '/Users/cheshier/Desktop/Learn/Node/Section 2/var.js',
loaded: true,
children: [],
paths: [Array]
}
],
paths: [
'/Users/cheshier/Desktop/Learn/Node/Section 2/node_modules',
'/Users/cheshier/Desktop/Learn/Node/node_modules',
'/Users/cheshier/Desktop/Learn/node_modules',
'/Users/cheshier/Desktop/node_modules',
'/Users/cheshier/node_modules',
'/Users/node_modules',
'/node_modules'
]
}
true
많은 정보를 알 수 있지만 require.cache와 require.main 속성에 주목해보자.
- require.cache : require 함수를 통해 읽어온 정보를 임시로 저장한다. 해당 모듈 내에서 require을 통해 불러온 정보는 내부에서 활용될 때 require.cache를 참조하게 된다.
- require.main : 불러온 모듈이 어디에 위치하는지 알 수 있다.
require 함수를 사용할 때에도 주의할 점이 있다. 다음과 같은 모듈들이 있다고 하자.
// dep1.js
require("./dep2.js");
// dep2.js
require("./dep1.js");
이 dep1과 dep2는 모듈의 입장에서 자신을 참조하는 모듈을 참조하고 있기 때문에, 이론적으로는 무한히 참조하는 '순환 참조' 상황을 만들고 있다.
Node는 이렇게 순환 참조 상황을 인지하면 알아서 순환 참조를 만드는 require 함수를 빈 객체로 만들어버리기 때문에 실제로 순환 참조가 일어나는 상황은 없겠지만, 애초에 이런 상황을 유발하는 코드를 작성하지 않도록 주의하자. 본인을 포함한 다른 개발자에게 혼란을 줄 수 있다.
3.3.2 ECMAScript 모듈
ECMAScript 모듈(이하 ES 모듈)은 공식 JS 모듈 형식이다. 브라우저는 이미 ES 모듈 형식을 채택하고 있으니, 이 모듈 형식에 익숙해지는 것이 장기적으로는 좋을 것이다.
ECMAScript 모듈 파일의 확장자는 기본적으로 .mjs이지만, .js로 설정해도 무방하다. 대신 .js 확장자의 파일을 모듈로 활용하려면, 이를 HTML에서 불러올 때는 **type="module"**을, Node에서는 package.json 파일에 type: module을 명시해야 사용할 수 있다는 점을 기억하자.
이제 앞서 CommonJS 형식으로 정의했던 모듈들을 ECMAScript 형식으로 선언해보자. 매우 간단하다.
// var.mjs
export const odd = "홀수입니다.";
export const even = "짝수입니다.";
// func.mjs
import { odd, even } from "./var.mjs";
function checkOddOrEven(num) {
if (num % 2) {
return odd;
}
return even;
}
export default checkOddOrEven;
// index.mjs
import { odd, even } from "./var.mjs";
import checkNumber from "./func.mjs";
function checkStringOddOrEven(str) {
if (str.length % 2) {
return odd;
}
return even;
}
console.log(checkNumber(10));
console.log(checkStringOddOrEven("hello"));
내보내고 싶은 정보를 export라는 키워드를 앞에 붙여 내보내고, 불러오고 싶은 정보는 import라는 키워드를 통해 불러온다.
export default는 해당 모듈에서 말 그대로 기본적으로 내보내고 싶은 정보를 명시하고 있고, 그렇기에 import해올 때 중괄호(Bracket)를 감싸지 않고도 가져올 수 있다.
또한 불러올 때 이름을 변경해도 괜찮은 것 또한 export default로 내보낸 정보의 특징이라고 할 수 있다.
그리고 CommonJS에서의 방식처럼 함수나 객체를 활용하는 것이 아니라, export, import라는 JavaScript 문법 자체를 활용하고 있는 점도 특징이다.
정리하면, CommonJS와 ECMAScript 방식의 모듈의 차이점은 다음과 같다.
3.3.3 다이내믹 임포트
다이내믹 임포트는 말 그대로 동적으로 모듈을 불러오는 기능이다. CommonJS 모듈은 이 기능을 지원하지만 ECMAScript 모듈은 지원하지 않는다.
// dynamic.js
const a = false;
if (a) {
require("./func");
}
console.log("성공!");
cjs 방식에서는 이렇게 조건부로 모듈을 불러오거나, 불러오지 않을 수 있다.
// dynamic.mjs
const a = false;
if (a) {
import "./func.js"; // SyntaxError
}
console.log("성공!");
// dynamic2.mjs
const a = true;
if (a) {
const m1 = await import("./func.mjs");
const m2 = await import("./var.mjs");
}
console.log(m1, m2); // 모듈 정보 ~~~
mjs 방식에서는 import 문이 항상 코드 최상단에 위치하고 있어야하기 때문에, cjs 방식에서 가능했던 것처럼 조건문 안에 작성하는 것이 불가능하다. 따라서 mjs에서 동적으로 모듈을 불러올 때에는 import()함수의 호출을 통해 모듈을 동적으로 불러오는 다른 방식을 사용하게 된다. import 함수는 프로미스를 리턴하기 때문에, 활용하려면 await을 앞에 붙여줘야한다. 그래서 사실 ES 모듈에서 기본 문법으로 다이내믹 임포트를 지원하지 않는 것은 맞지만, 다이내믹 임포트 자체가 불가능한 것은 아니다.
3.3.4 __filename, __dirname
CommonJS 모듈에서는 현재 파일과 디렉토리의 경로를 알기 위해 사용할 수 있는 __filename과 __dirname이라는 키워드를 제공한다.
_(언더스코어)를 접두사처럼 두 개 붙인 filename과 dirname이라서 "더블 언더스코어 filename"처럼 읽는 줄 알았는데, 줄임말(Double Underscore -> Dunderscore)을 써서 "Dunderscore filename"이라고 읽는 방법도 있는 것 같다. (규칙은 아니니까 그냥 그런갑다 하자)
// filename.js
console.log(__filename); // 경로~~/filename.js
console.log(__dirname); // 경로~~
ES 모듈은 이 키워드를 사용할 수 없다. 단, 파일 경로에 대해 import.meta.url을 사용할 수 있다.
// filename.mjs
console.log(import.meta.url); // 경로~~/filename.mjs
3.4 노드 내장 객체 알아보기
우리가 앞서 require, module, console 등의 객체를 따로 불러오지 않고도 활용할 수 있었던 이유는 이게 모두 노드의 내장 객체에 해당하기 때문이다.
노드에서 자주 활용되는 내장 객체들에는 어떤 것들이 있는지 알아보자.
- global : 노드의 전역 객체이다. 브라우저 상에서 window 객체와 같은 역할
- console : global 객체에 내장돼있다. 보통 디버깅을 위해 활용
- 타이머 : global 객체에 내장돼있다. setTimeout, setImmediate, setInterval 등
- process : 현재 실행되고 있는 노드 프��로세스에 대한 정보를 포함
3.4.1 global
global은 전역 객체이므로, 모든 파일에서 접근할 수 있다는 특성을 갖는다. 브라우저의 window와 같은 역할을 하며, window.open을 그냥 open으로 호출할 수 있는 것처럼 global은 생략할 수 있다. 즉, console, setTimeout을 global.console, global.setTimeout으로 호출하지 않아도 된다.
global의 내부를 노드에서 확인하려면 REPL에서 global을 통해 확인하거나, 모듈에서 console.log(globalThis)를 통해 확인할 수 있다.
이 때 globalThis는 환경에 따라 동적으로 전역 객체에 바인딩되는 객체이며, 브라우저 환경에서 window를, 노드 환경에서는 global을 가리키게 된다.
global 객체는 모든 파일에서 접근할 수 있다는 특성을 갖고 있어 값을 대입하면 다른 파일에서도 해당 값을 쉽게 참조할 수 있는데, 그렇다고 global 객체를 남용하면 안된다. C언어를 배울 때 전역 변수를 남용하면 안된다고 배웠을텐데, 같은 맥락이다.
3.4.2 console
console은 global에 내장되어있는 객체로, 특정 시점에 변수에 값이 제대로 할당되었는지, 에러의 내용이 무엇인지 알기 위해 등 보통 디버깅을 위해 활용하게 된다.
아주 대표적인 메서드는 console.log()이다. 하지만 다양한 상황에서 활용할 수 있는 이외의 메서드들도 많이 있다. 예제를 통해 활용해보자.
const string = "abc";
const number = 1;
const boolean = true;
const obj = {
outside: {
inside: {
key: "value",
},
},
};
console.time("전체시간");
console.log("평범한 로그입니다. 쉼표로 구분해 여러 값을 찍을 수 있습니다.");
console.log(string, number, boolean);
console.error("에러 메시지는 console.error에 담아주세요.");
console.table([
{ name: "제로", birth: 1994 },
{ name: "hero", birth: 1988 },
]);
console.dir(obj, { colors: false, depth: 2 });
console.dir(obj, { colors: true, depth: 1 });
console.time("시간 측정");
for (let i = 0; i < 100000; i++) {}
console.timeEnd("시간 측정");
function b() {
console.trace("에러 위치 추적");
}
function a() {
b();
}
a();
console.timeEnd("전체시간");
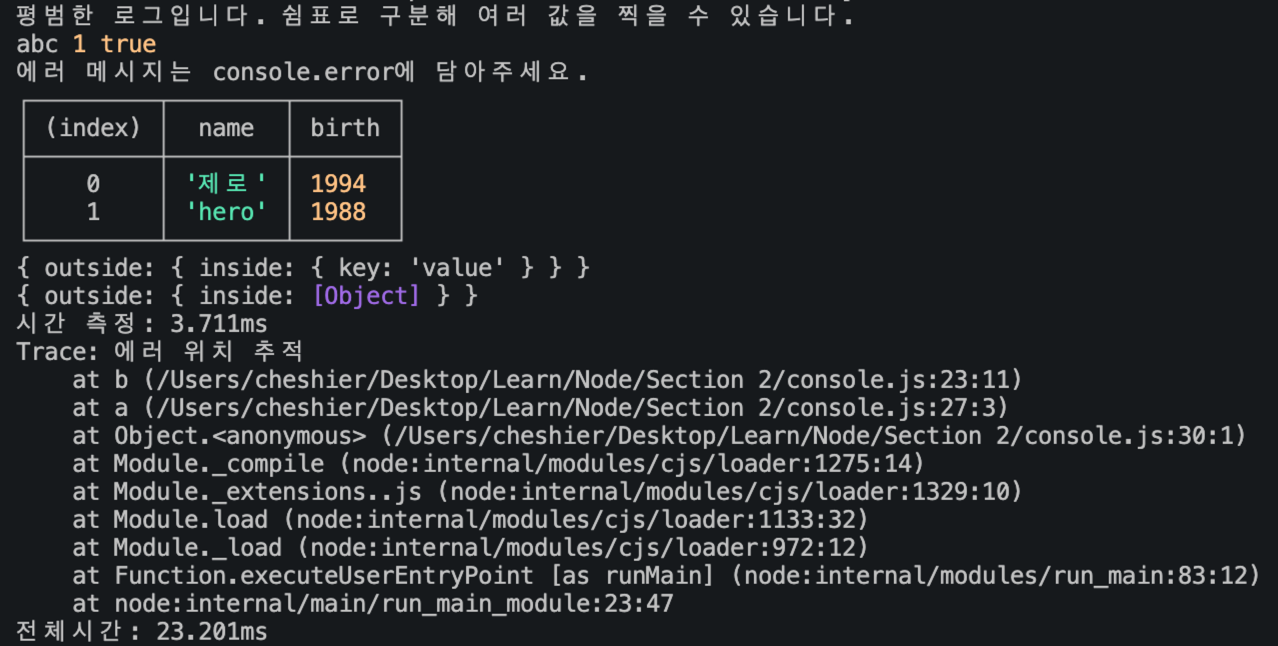
여기서 console.log()가 아닌 다른 메서드를 확인할 수 있다.
-
console.time(레이블): console.timeEnd(레이블)과 대응되고, 같은 레이블을 가진 해당 메서드의 호출 시점까지의 시간을 측정
-
console.log(내용): 내용을 콘솔에 표시. console.log(내용1, 내용2, 내용3, ...)등과 같이 여러 내용을 한번에 출력하는 것도 가능
-
console.err(에러): 에러를 콘솔에 표시.
-
console.table(배열): 배열의 요소로 객체 리터럴을 넣으면 객체의 속성들이 테이블 형식으로 표현.
-
console.dir(객체, 옵션): 객체를 콘솔에 표시할 때 사용. 옵션의 colors를 true로 설정하면 출력되는 내용에 색상이 추가되며, depth는 표시할 객체의 깊이를 설정한다. 기본값은 2로 설정되어있다.
-
console.trace(레이블): 에러가 어디에서 발생했는지 추적할 수 있다. 에러 내용 만으로는 에러가 발생한 위치를 알기 힘들 때 사용
이 예제를 실행한 결과는 다음과 같다.
3.4.3 타이머
시간과 관련된 작업을 실행하고 싶을 때 주��로 활용하는 함수 setTimeout, setInterval, setImmediate 3가지가 있다.
- setTimeout(콜백, 밀리초) : 주어진 밀리초 이후에 콜백을 실행
- setInterval(콜백, 밀리초) : 주어진 밀리초마다 콜백을 반복 실행
- setImmediate(콜백) : 콜백을 즉시 실행
타이머 함수들은 반환값에 각 함수의 ID를 포함한다. setTimeout과 setInterval은 이 ID를 이용해 작업을 취소할 수 있다.
- clearTimeout(ID) : ID에 해당하는 setTimeout을 취소
- clearInterval(ID) : ID에 해당하는 setInterval을 취소
- clearImmediate(ID) : ID에 해당하는 setImmediate를 취소
참고로 setImmediate(cb)와 setTimeout(cb, 0)은 모두 이벤트 루프를 거쳐 콜백을 실행하지만, 파일 시스템 접근, I/O 작업의 cb에서 이 둘을 호출한다면 setImmediate가 먼저 실행된다. 하지만 혼동을 피하기 위해 콜백을 즉시 실행하도록 하고 싶다면 setImmediate를 활용하도록 하자.
타이머는 콜백 기반으로 동작하는 API이지만, 대표적인 비동기 함수이기 때문에 프로미스 기반의 형태로도 존재한다.
//promiseTimer.mjs
import { setTimeout, setInterval } from "timers/promises";
await setTimeout(3000);
console.log("3초 후 실행");
for await (const startTime of setInterval(1000, Date.now())) {
console.log("1초마다 실행", new Date(startTime));
}
3초 후 실행
1초마다 실행 2023-12-10T09:10:39.242Z
1초마다 실행 2023-12-10T09:10:39.242Z
1초마다 실행 2023-12-10T09:10:39.242Z
1초마다 실행 2023-12-10T09:10:39.242Z
1초마다 실행 2023-12-10T09:10:39.242Z
1초마다 실행 2023-12-10T09:10:39.242Z
1초마다 실행 2023-12-10T09:10:39.242Z
3.4.4 process
process는 현재 실행 중인 노드 프로세스에 대한 정보를 담고 있는 객체로서, 굉장히 다양한 정보를 담고 있지만, 이 모든 정보들을 항상 활용하지는 않기 때문에 알아두면 좋을 속성들에 대해서 먼저 살펴보자.
-
process.version : 설치된 Node.js의 버전
-
process.execPath : 설치된 Node.js의 경로
-
process.arch : 프로세서의 아키텍처 버전
-
process.platform : 운영체제 플랫폼 정보
-
process.pid : 현재 프로세스의 id
-
process.uptime() : 현재 프로세스의 실행 시간
-
process.cwd() : 현재 프로세스의 실행 위치
-
process.cpuUsage() : 현재 CPU 사용량
중요하지만 위 목록에 없는 속성에 대해서는 아래에서 다룬다.
3.4.4.1 process.env
시스템의 환경 변수 정보를 담고 있다. 비밀 정보(DB 접근 비밀번호, API 키 등)를 보관하는 용도로도 사용된다.
const secretId = process.env.SECRET_ID;
const secretCode = process.env.SECRET_CODE;
하지만 노드의 실행에 영향을 주는 환경 변수들도 존재한다.
NODE_OPTIONS=--max-old-space-size=8192
UV_THREADPOOL_SIZE=8
NODE_OPTIONS는 노드의 실행 옵션이다. 그리고 예시로 위에서 할당되고 있는 --max-old-space-size는 노드가 사용할 수 있는 메모리 8GB로 제한하는 옵션이다.
UV_THREADPOOL_SIZE는 스레드풀 개수를 지정한다.
3.4.4.2 process.nextTick(콜백)
process.nextTick()은 인자로 넘긴 콜백을, 현재 실행이 예약된 다른 콜백보다 먼저 실행하고 싶을 때 활용하는 메서드이다. 아래 예제를 보자.
setImmediate(() => {
console.log("immediate");
});
process.nextTick(() => {
console.log("nextTick");
});
setTimeout(() => {
console.log("timeout");
}, 0);
Promise.resolve().then(() => console.log("promise"));
이 예제의 실행 결과는 다음과 같다.
nextTick
promise
timeout
immediate
이 예제의 실행 결과를 이해하려면 태스크 큐에 대해 알아야 한다.
태스크 큐는 마이크로 태스크를 위한 것과, 매크로 태스크를 위한 것으로 나뉘는데, 타이머 함수의 콜백은 매크로 태스크 큐로, process.nextTick과 Promise의 콜백은 마이크로 태스크 큐로 넘어간다.
그리고 이벤트 루프의 입장에서 마이크로 태스크 큐의 실행 우선 순위가 매크로 태스크 큐보다 높기 때문에, 마이크로 태스크 큐에 등록된 콜백을 모두 호출 스택으로 끌어온 뒤에 실행하고 호출 스택이 다 비게 되면 매크로 태스크 큐에 등록된 콜백을 끌어온다. 그래서 저런 결과가 나온다.
3.4.4.3 process.exit(코드)
이 메서드는 호출되면 호출한 주체인 노드 프로세스를 종료한다. 그래서 특성상 서버로서 실행되고 있는 노드의 환경에서는 잘 호출하지 않고, 독립적인 노드 프로그램에서 수동으로 이를 종료시키기 위해 사용한다.
process.exit()은 인수로 0 또는 1의 코드를 넘겨줄 수 있는데, 코드에 따라 작동 방식이 달라진다.
-
process.exit(0) : 정상 종료
-
process.exit(1) : 비정상 종료 (ex: 에러 발생 상황)
3.4.5 기타 내장 객체
-
URL, URLSearchParams
-
AbortController, FormData, fetch, Headers, Request, Response, Event, EventTarget
-
TextDecoder, TextEncoder
-
WebAssembly
3.5 노드 내장 모듈 사용하기
노드의 내장 모듈은 노드 버전에 따라 상이할 수 있으나, 버전과 상관없이 안정적이고 유용한 기능을 제공하는 모듈들과 관련 메서드들을 한번 알아보자.
물론 이런 류의 지식은 공식 문서 기반으로 공부하는 것이 매우 매우 좋으니 한번 살펴봐야한다. Node.js v20(현재 최신 LTS) API Docs - https://nodejs.org/docs/latest-v20.x/api/index.html
3.5.1 os
os 모듈은 노드의 내장 모듈 중 하나로서, 운영체제의 정��보를 가져온다. 성능 모니터링, CPU 코어 개수에 따라 가동할 서버의 개수 파악 등에 이 os 모듈을 활용할 수 있다. 아래는 자주 활용하는 메서드 목록이다.
- 운영체제 정보 관련
os.arch()os.platform()os.type()os.uptime()os.hostname()os.release()
- 경로 관련
os.homedir()os.tmpdir()
- cpu 정보 관련
os.cpus()
- 메모리 정보 관련
os.freemem()os.totalmem()
3.5.2 path
path 모듈은 폴더와 파일의 경로를 쉽게 조작할 수 있게하는 모듈이다. Windows 계열과 POSIX 계열 운영체제의 경로 구분자가 다르기 때문에 발생할 수 있는 문제에서 이 path 모듈은 큰 도움이 될 것이다. 아래는 자주 활용하는 메서드 목록이다.
- 구분자
path.sep()path.delimiter
- 경로, 파일명
path.dirname(string)path.extname(string)path.basename(string)
- 포맷팅, 정규화
path.parse(string)path.format({ dir: string, name: string, ext: string })path.normalize(string)
- 이외
path.isAbsolute(string)path.relative(string)path.join()path.resolve()
3.5.3 url
url 모듈은 인터넷 주소를 쉽게 조작할 수 있게하는 모듈이다. url 처리 방식은 WHATWG 방식과 그 이전 방식으로 나뉘는데, 요즘은 전자만 활용한다. (웹 표준이기 때문) URL 객체는 username, password, origin, searchParams 등의 속성이 존재하는데, 이 searchParams 또한 Iterator 객체로서, 클라이언트에서 쿼리스트링으로 요청을 보내면 이 객체에 데이터가 담기게 된다. 따라서 아래와 같은 메서드를 활용할 수 있다.
searchParams.getAll()searchParams.get()searchParams.has()searchParams.keys()searchParams.values()searchParams.append()searchParams.set()searchParams.delete()searchParams.toString()
3.5.4 dns
DNS(Domain Name System)를 다룰 때 사용하는 모듈이다. 주로 도메인 주소를 통해 IP 주소를 알아내거나 하는 상황에서 활용한다.
- dns.lookup(domain)
- dns.resolve(domain, recordName) // recordName : A, AAAA, CNAME, MX ...
3.5.5 crypto
암호화를 담당하는 모듈이다. 고객의 계정 ID, 비밀번호, 각종 개인정보 등 유출 시 매우 심각한 위험을 초래할 수 있는 민감한 정보는 DB에 절대절대 평문으로 저장하면 안되기에 이 모듈을 활용해서 암호화를 해야한다.
3.5.5.1 단방향 암호화
복호화가 불가능한 암호화 방식을 단방향 암호화라고 한다. 주로 비밀번호같이 복호화할 필요가 없는 데이터를 암호화할 때 해당 방식을 채택한다. 단방향 암호화는 해시 기법을 사용해서 진행하게 된다. 활용 예시를 살펴보자.
const crypto = require("crypto");
console.log(
"base64: ",
crypto.createHash("sha512").update("password").digest("base64")
);
위 예시에서는 sha512 해시 알고리즘을 활용해서 비밀번호 평문을 해싱하고 그것을 base64로 인코딩했다.
하지만 해시 알고리즘은 가끔 전혀 다른 문자열에 대해 동일한 출력값을 반환해서 충돌을 내기도 하는데, 이 경우 보안 취약점으로 이어질 수 있으므로, 해시 알고리즘은 항상 최신화하는게 좋다. 현재는 pbkdf2, bcrypt, scrypt 등의 알고리즘을 활용해 암호화를 수행한다. (Node에서는 pbkdf2, scrypt 지원)
3.5.5.2 양방향 암호화
양방향 암호화는 복호화가 가능하며 복호화에 활용되는 Key가 존재한다. 암호화할 때 사용한 Key를 동일하게 사용해야만 복호화가 가능하다. 양방향 암호화는 암호학을 추가로 공부(AES 암호화 등)해야만 완벽히 이해하고 코드를 작성할 수 있으므로, 지금은 활용할 수 있는 메서드 목록과 예시코드만 살펴보자.
const crypto = require('crypto');
const algorithm = 'aes-256-cbc';
const key = 'abcdefghijklmnopqrstuvwxyz123456';
const iv = '1234567890123456';
const cipher = crypto.createChiperiv(algorithm, key, iv);
let result = cipher.update('암호문', 'utf8', 'base64');
result += chipher.final('base64') // 암호화
const decipher = crypto.createDecipheriv(algorithm, key, iv);
let result2 = decipher.update(result. 'base64', 'utf8');
result2 += decipher.final('utf8'); // 복호화
하지만 좀 더 간단하게 암호화하고 싶으면 crypto-js 라는 라이브러리도 좋은 옵션.
3.5.6 util
각종 편의 기능을 모아놓은 모듈이다! 많은 API가 추가되기도하고, 사라지기도(deprecated) 한다. 유용한 메서드 두개만 짚고 가보자.
- util.deprecate()
- util.promisify()
const util = require("util");
const crypto = require("crypto");
const dontUseMe = util.deprecate((x, y) => {
console.log(x + y);
}, "dontUseMe 함수는 deprecated되었으니 더 쓰지 마세요!");
dontUseMe(1, 2);
const randomBytePromise = util.promisify(crypto.randomBytes);
randomBytesPromise(64)
.then((buf) => {
console.log(buf.toString("base64"));
})
.catch((error) => {
console.error(error);
});
3.5.7 worker_threads
이 모듈은 싱글 스레드 기반의 환경인 노드에서 멀티 스레드 방식으로 작업을 처리할 수 있도록 하는 모듈이다. 아래 예제 코드를 보자.
// worker_threads.js
const { Worker, isMainThread, parentPort } = require("worker_threads");
if (isMainThreads) {
// 메인 스레드
const worker = new Worker(__filename);
worker.on("message", (message) => console.log("from worker", message));
worker.on("exit", () => console.log("worker exit"));
worker.postMessage("ping");
} else {
// 워커 스레드
parentPort.on("message", (value) => {
console.log("from parent", value);
parentPort.postMessage("pong");
parentPort.close();
});
}
노드의 멀티스레드는 메인 스레드를 제외한 워커 스레드가 작업을 할당받으면, 해당 작업들의 처리 결과를 메인 스레드로 전달한 뒤, 메인 스레드가 최종적으로 작업 처리 결과를 반환하는 식으로 이루어진다. 물론 이 모든 과정은 수동으로 이루어진다.
메인 스레드에서 여러 개의 워커 스레드를 생성해서 작업을 처리하려면 어떻게 해야할까?
// worker_data.js
const {
Worker,
isMainThread,
parentPort,
workerData,
} = require("worker_threads");
if (isMainThread) {
// 부모일 때
const threads = new Set();
threads.add(
new Worker(__filename, {
workerData: { start: 1 },
})
);
threads.add(
new Worker(__filename, {
workerData: { start: 2 },
})
);
for (let worker of threads) {
worker.on("message", (message) => console.log("from worker", message));
worker.on("exit", () => {
threads.delete(worker);
if (threads.size === 0) {
console.log("job done");
}
});
}
} else {
// 워커일 때
const data = workerData;
parentPort.postMessage(data.start + 100);
}
위와 같이 여러 개의 워커를 생성한 뒤 반복문을 돌며 작업을 수행하고, 각 워커의 작업이 종료되면 해당 워커를 지워주는 식(메모리 효율상 권장)으로 코드를 작성할 수 있다.
이렇게 멀티 스레드를 활용해서 처리하면 좋을 작업은 어떤 경우일까? 당연하게도 아주 많은 연산이 필요한 작업의 경우 멀티 스레드를 활용하는게 좋다.
예를 들어 어떤 수의 소수를 대신 찾아주는 서비스를 구축한다고 할 때, 하나의 메인 스레드로 소수를 찾는 작업을 지시하면 그 수가 작은 경우엔 그닥 문제가 없겠지만 큰 수의 소수를 찾을 때는 소수를 찾는 동안 서비스가 멈춰버릴 수도 있다. 그런 경우에 메인 스레드에서 워커들에게 작업을 분배하고, 메인은 사용자들의 요청을 처리하고 워커들이 계산한 결과를 반환하는 역할만 수행하도록 할 수 있다.
하지만 원래 노드는 멀티 스레드 기반 작업에 적합한 언어가 아니기 때문에, 아주 간단한 형태의 문제가 아니라면 다른 언어를 채택해서 접근하는 것이 좋을 것이다.
3.5.8 child_process
이전 섹션과 내용을 조금 이어가보자. 다른 언어를 채택해서 접근한다는게 어떤 의미일까? 노드로 서버 만들지 말고 자바의 Spring이나 파이썬의 Flask같은 프레임워크를 활용해서 서버를 만들라는 의미일까? 아니다. 노드는 child_process 모듈을 활용하면 다른 언어로 만들어진 프로그램을 호출할 수 있다.
const exec = require("child_process").exec;
const process = exec("dir"); // 명령어. 리눅스의 맥은 ls를 넣자
process.stdout.on("data", function (data) {
console.log(data.toString());
}); // 실행 결과
process.stderr.on("data", function (data) {
console.error(data.toString());
}); // 실행 에러
위 예제에서 프로그램 실행이 성공하면 그 결과가 표준 출력에서, 실패하면 그 결과가 표준 에러에서 나타나게 된다.
이번엔 파이썬으로 작성된 프로그램을 실행해보자.
const spawn = require("child_process").spawn;
const process = spawn("python", ["test.py"]);
process.stdout.on("data", function (data) {
console.log(data.toString());
}); // 실행 결과
process.stderr.on("data", function (data) {
console.error(data.toString());
}); // 실행 에러
주의할 점은 노드 자체에서 파이썬을 실행해서 해당 프로그램의 실행 결과를 가져오는 것이 아니고, 노드가 실행되고 있는 컴퓨터에게 해당 프로그램을 실행해달라고 '요청'하는 것이기 때문에 다른 언어의 실행환경이 노드가 실행되고 있는 환경에 이미 갖춰져있어야한다는 것이다.
3.5.9 기타 모듈들
- async_hooks: 비동기 코드의 흐름을 추적할 수 있는 실험적인 모듈
- dgram: UDP와 관련된 작업을 할 때 사용
- net: HTTP보다 로우 레벨인 TCP, IPC 통신을 할 때 사용
- perf_hooks: 성능을 측정할 때
console.time보다 더 정교하게 측정 - querystring:
URLSearchParams가 나오기 이전에 쿼리스트링을 다루기 위해 사용했던 모듈.URLSearchParams를 사용하자. - string_decoder: 버퍼 데이터를 문자열로 바꾸는 데 사용
- tls: TLS와 SSL에 관련된 작업을 할 때 사용
- tty: 터미널과 관련된 작업을 할 때 사용
- v8: v8 엔진에 직접 접근할 때 사용
- vm: 가상 머신에 직접 접근할 때 사용
- wasi: 웹어셈블리를 실행할 때 사용하는 실험적인 모듈
- assert: 테스트 할 때 사용
3.6 파일 시스템 접근하기
노드에서는 파일 시스템에 접근하는 fs라는 모듈이 있다. 이 모듈을 활용하면 로컬 컴퓨터에 저장된 파일을 읽거나 생성, 수정 혹은 삭제 또한 가능하게 된다. 따라서 이 fs 모듈을 활용하는 코드는 정보보안적 측면에서도 각별히 주의되어 관리될 필요가 있다. 내포된 잠재적 위험성과 별개로, fs 모듈은 매우 유용한 모듈이다. 아래의 예제를 보자.
const fs = require("fs");
fs.readFile("./readme.txt", (err, data) => {
if (err) {
throw err;
}
console.log(data);
console.log(data.toString());
});
임의의 텍스트 파일을 읽어온 결과를 바이너리 데이터와 스트링 데이터로 출력하는 예제이다. 노드의 모듈을 활용할 때 콜백을 파라미터로 넘기는 경우라면 저렇게 err와 data를 인자로 갖는 콜백 형태가 되는데, 콜백 헬의 여지도 있고, 프로미스에 더 익숙한 사람들은 아래와 같은 방식으�로 promisify를 수행해서 모듈을 활용할 수 있다.
const fs = require("fs").promises;
fs.readFile("./readme.txt")
.then((data) => {
console.log(data);
console.log(data.toString());
})
.catch((err) => {
console.error(err);
});
이외에도 파일을 생성할 때는 fs.writeFile(), 파일을 삭제할 때는 fs.unlink(), 파일의 이름을 변경할 때는 fs.rename() 등의 메서드를 활용하면 된다.
3.6.1 동기 메서드와 비동기 메서드
동기와 비동기의 차이는 뭘까? 간단하게 생각하면 실행 순서의 보장 여부일 것이다.
동기적인 코드는 인간의 입장에서 직관적이고 이해하기 편하다. 그냥 위에서 아래로, 왼쪽에서 오른쪽으로 읽으면 코드의 동작 흐름을 파악하는 데 큰 문제가 없다.
하지만 비동기적인 코드는 그렇게 동작하지 않는다. 먼저 실행된 코드가 나중에 실행된 코드보다 늦게 끝날 수도 있는 것이다. 그래서 직관적이지 않고 이해하기도 어려운 편이다.
이 동기와 비동기의 동작 흐름은 싱글 스레드 기반인 노드의 특성과 블로킹, 논블로킹 동작 방식과의 조합에 기인한다.
어떤 일련의 작업들을 처리함에 있어 동기-블로킹 방식은 비동기-논블로킹 방식의 효율성을 따라올 수 없다. 그렇지만 앞서 서술한 바와 같이 비동기적인 코드의 동작 흐름을 파악하는 것은 매우 어렵기에, 코드가 비동기-논블로킹 방식으로 동작하면서 동기적인 흐름을 보이도록 하는 콜백, 프로미스, async / await 구문 등의 방법들이 존재한다.
그렇다면 동기-블로킹 방식의 코드는 필요가 없을까? 그건 아니다. 일련의 작업들이 실행될 때 후순위의 작업들이 선순위 작업이 처�리됨에 따라 지연되었을 때 장점보다 단점이 더 많다면 당연히 좋지 않겠지만, 딱 한번 실행되는 작업은 동기적인 코드로 작성해도 무관하다.
초기화 작업을 예로 들 수 있을 것이다. 여러번 실행될 필요 없이 딱 한번 실행되고, 개발자가 의도한 일련의 단계를 거칠 필요가 있다면 동기적인 코드로 작성하는 것이 좋다.
fs 모듈에서는 이런 상황에서 동기적인 코드를 작성할 수 있도록 Sync 버전의 메서드도 지원하고 있다.
const fs = require("fs");
console.log("시작");
let data = fs.readFileSync("./readme2.txt");
console.log("1번", data.toString());
data = fs.readFileSync("./readme2.txt");
console.log("2번", data.toString());
data = fs.readFileSync("./readme2.txt");
console.log("3번", data.toString());
console.log("끝");
이걸 비동기-논블로킹 방식의 코드로 작성하면 아래와 같아진다. 콜백 패턴의 예제 코드를 확인해보자.
const fs = require("fs");
console.log("시작");
fs.readFile("./readme2.txt", (err, data) => {
if (err) {
throw err;
}
console.log("1번", data.toString());
fs.readFile("./readme2.txt", (err, data) => {
if (err) {
throw err;
}
console.log("2번", data.toString());
fs.readFile("./readme2.txt", (err, data) => {
if (err) {
throw err;
}
console.log("3번", data.toString());
console.log("끝");
});
});
});
위 예제의 실행 결과는 Sync 방식과 같다. 그러면 Sync 방식과 차이가 없는게 아닌가? -> 맞다. 이 파일 하나의 관점에서 동작 방식의 차이는 근본적으로 없다. (1번 끝 -> 2번 끝 -> 3번 끝)
하지만 앞서 설명한 성능상의 효율은 위와 같은 코드 파일이 수십개가 실행될 때 나타난다. 동기-블로킹 방식은 수십개의 파일 간에도 블로킹이 일어나서 성능 저하가 매우 심한 반면 비동기-논블로킹 방식은 그 파일들이 백그라운드에서 모두 동시에 실행되기 때문에 성능 효율 면에서 이점이 있는 것이다.
그래도 콜백 패턴은 가독성 면에서 너무 좋지 않다. 프로미스 또는 async / await 구문으로 변경해보자.
const fs = require("fs").promises;
console.log("시작");
fs.readFile("./readme2.txt")
.then((data) => {
console.log("1번", data.toString());
return fs.readFile("./readme2.txt");
})
.then((data) => {
console.log("2번", data.toString());
return fs.readFile("./readme2.txt");
})
.then((data) => {
console.log("3번", data.toString());
console.log("끝");
})
.catch((err) => {
console.error(err);
});
우선 프로미스 패턴이다. 코드의 Depth가 깊어져도 이제 더 이상 indent level이 늘어나는 일은 없다. 하지만 ES2022에서 지원하기 시작한 top level await을 적용한 코드가 가장 좋은 가독성을 제공한다고 생각한다.
const fs = require("fs").promises;
console.log("시작");
let data = await fs.readFile("/readme.txt");
console.log("1번", data.toString());
data = await fs.readFile("/readme.txt");
console.log("2번", data.toString());
data = await fs.readFile("/readme.txt");
console.log("3번", data.toString());
data = await fs.readFile("/readme.txt");
console.log("4번", data.toString());
동기적으로 작성된 코드와 별반 차이가 없다.
3.6.2 버퍼와 스트림 이해하기
버퍼와 스트림을 이해할 때는 동영상 플레이어를 떠올리면 좋다.
예전에 윈도우에서 기본으로 지원하던 동영상 플레이어인 Windows Media Player가 있었는데, 2000년도 초반에 그 플레이어로 영화 파일을 재생하면 초기 또는 중간 중간 '버퍼링 중...' 이라는 문구를 볼 수 있었다.
버퍼는 무엇일까? 원래 버퍼는 어떤 파일을 읽어들일 때 병목 현상(Throttling)을 막기 위해 도입된 응용 프로그램 단과 저수준 파일 입력 단 중간에 위치한 작은 메모리 공간이다. 설정한 크기만큼 파일을 먼저 읽어들인 뒤, 버퍼가 채워졌을 때 그것을 응용 프로그램에서 요청하면 보내준다. 그래서 버퍼링은 버퍼가 파일 입력 단에서 파일을 읽어들이고 있는, 버퍼를 채우는 작업을 의미하는 것이다.
그렇다면 스트림은 무엇일까? 스트림은 보통 인터넷을 통해 대용량 데이터를 읽거나 쓸 때 적용되며, 온라인 스트리밍 방송을 떠올리면 된다. 실시간으로 송출되는 영상, 음성 데이터는 그 크기가 매우 큰 편이며, 영상의 해상도가 높아질수록 크기는 더욱 늘어날 것이다. 이걸 클라이언트에서 끊��김없이 재생하기 위해선 버퍼를 도입하되, 기존의 버퍼처럼 버퍼가 모두 채워질때까지 기다리지 않고, 주기적으로 클라이언트에 보내줘야 할 것이다.
그래서 요약하면 버퍼는 데이터를 버퍼의 크기만큼 나눠서 전달하고, 스트림은 버퍼의 크기만큼은 아니어도 일정한 주기로 데이터를 나눠서 전달한다는 차이가 있다.
노드에서 버퍼를 사용하는 방법을 알아보자.
const buffer = Buffer.from("저를 버퍼로 바꿔보세요");
console.log("from():", buffer);
console.log("length:", buffer.length);
console.log("toString():", buffer.toString());
const array = [
Buffer.from("띄엄 "),
Buffer.from("띄엄 "),
Buffer.from("띄어쓰기"),
];
const buffer2 = Buffer.concat(array);
console.log("concat():", buffer2.toString());
const buffer3 = Buffer.alloc(5);
console.log("alloc():", buffer3);
노드에서는 기본적으로 Buffer 객체를 활용하며, Buffer.from() 메서드로 데이터를 버퍼에 채울 수 있다. 여러개의 버퍼를 연결할 때는 .concat(), 빈 버퍼를 할당받을 때는 .alloc()을 사용하면 된다.
스트림은 어떨까?
const fs = require("fs");
const readStream = fs.createReadStream("./readme3.txt", { highWaterMark: 16 }); // 16 Byte Seperated
const data = [];
readStream.on("data", (chunk) => {
data.push(chunk);
console.log("data :", chunk, chunk.length);
});
readStream.on("end", () => {
console.log("end :", Buffer.concat(data).toString());
});
readStream.on("error", (err) => {
console.log("error :", err);
});
fs 모듈의 createReadSteam() 메서드를 활용해서 읽기 스트림을 만들 수 있다. (쓰기는 createWriteStream). 이 메서드는 한 번에 64kb 크기의 데이터를 읽어내며, 이를 임의로 조정하기 위해서는 highWaterMark 옵션을 활용하면 된다.
스트림도 비동기 메서드이므로 에러처리를 꼭 해줘야한다.
readStream에서 받는 이벤트는 data, end, error가 있고, writeStream에서 받는 이벤트는 finish, close, error가 있다. 각 스트림의 .on() 메서드는 이벤트 리스너로서, 각 상황에 맞는 로직을 작성해주면 된다.
스트림끼리 연결해줄수도 있다! 스트림의 pipe() 메서드를 활용하면 된다.
const fs = require("fs");
const readStream = fs.createReadStream("readme4.txt");
const writeStream = fs.createWriteStream("writeme3.txt");
readStream.pipe(writeStream);
위 코드를 실행하면 readme4.txt와 똑같은 내용의 writeme3.txt가 생성된다. 앞서 서술했던 data 이벤트 리스너를 활용해서 똑같은 로직을 구현할 수 있지만 이렇게 pipe 메서드를 활용하면 더 간단하게 구현할 수 있다. 이 pipe는 다른 pipe 메서드의 후속 처리 메서드로서 동작하기도 해서 굉장히 유용한 것 같다. (체이닝이 가능하다는 말)
그렇지만 체이닝한 코드가 너무 길어질 수도 있는데, 그럴 때는 stream 모듈의 pipeline을 활용하는 방법도 있다.
import { pipeline } from "stream/promises";
import zlib from "zlib";
import fs from "fs";
await pipeline(
fs.createReadStream("./readme4.txt"),
zlib.createGzip(),
fs.createWriteStream("./readme4.txt.gz")
);
zlib는 노드에서 제공하는 압축 기능을 내장하는 모듈이다. zlib.createGzip()은 스트림을 지원하므로, 다른 스트림 메서드들과 같이 이렇게 pipeline 안에서 묶일 수 있다.
pipeline 메서드의 또 다른 장점은 AbortController를 활용해서 원할 때 파이프를 중단할 수도 있다는 점이다.
import { pipeline } from "stream/promises";
import zlib from "zlib";
import fs from "fs";
const ac = new AbortController();
const signal = ac.signal;
setTimeout(() => ac.abort(), 1); // 1ms 뒤에 중단
await pipeline(
fs.createReadStream("./readme4.txt"),
zlib.createGzip(),
fs.createWriteStream("./readme4.txt.gz"),
{ signal }
);
pipeline의 마지막 인수로 { signal }을 전달한 뒤, 원하는 시점에 ac.abort()를 호출하면 된다.
마지막으로, 실제 대용량 파일을 복사할 때 버퍼와 스트림 간 메모리 효율성을 비교해보는 예제를 살펴보자. 우선 아래와 같이 1GB 크기의 파일을 생성해줄 수 있다.
const fs = require("fs");
const file = fs.createWriteStream("./big.txt");
for (let i = 0; i <= 10000000; i++) {
file.write(
"안녕하세요. 엄청나게 큰 파일을 만들어 볼 것입니다. 각오 단단히 하세요!\n"
);
}
file.end();
process 객체의 memoryUsuage() 메서드를 활용하면 메모리 사용량을 알 수 있다. rss는 Resident Set Side로서, 콘솔에 출력해보면 주 메�모리에서 프로세스가 차지하는 공간의 크기를 알 수 있다.
// 버퍼
const fs = require("fs");
console.log("before: ", process.memoryUsage().rss);
const data1 = fs.readFileSync("./big.txt");
fs.writeFileSync("./big2.txt", data1);
console.log("buffer: ", process.memoryUsage().rss);
// 스트림
const fs = require("fs");
console.log("before: ", process.memoryUsage().rss);
const readStream = fs.createReadStream("./big.txt");
const writeStream = fs.createWriteStream("./big3.txt");
readStream.pipe(writeStream);
readStream.on("end", () => {
console.log("stream: ", process.memoryUsage().rss);
});

3.6.3 기타 fs 메서드 알아보기
fs 모듈은 파일 시스템을 다루기 위한 모듈이기 때문에 정말정말 많은 기능을 제공한다. 앞서 알아봤던 기능 외에도 파일, 디렉토리에 관한 거의 모든 기능을 다 구현하고 있다.
fs.access(path, option, cb)-> 파일이나 디렉토리의 접근 권한 확인fs.mkdir(path, cb)-> 디렉토리 생성fs.open(path, option, cb)-> 파일의 id를 불러옴fs.rename(oldPath, newPath, cb)-> 파일의 이름을 변경fs.readdir(path, cb)-> 디렉토리 내 파일 확인fs.unlink(path, cb)-> 파일 삭제fs.rmdir(path, cb)-> 빈 디렉토리 삭제fs.copyFile(oldPath, newPath, cb)-> 파일 복사fs.watch(target, eventHandler)-> target의 변경 탐지
3.6.4 스레드 풀 알아보기
앞서 서술한 fs, crypto, zlib, dns.lookup 모듈의 메서드는 실행 시 백그라운드에서 비동기적으로 동작한다. 그런데 궁금한 점. 이 갯수에 한계가 있을까? 메모리 허용치까지 무한정일까?
이 물음의 답이 스레드 풀의 개념과 이어진다. 노드는 기본적으로 백그라운드에서 동작하는 것을 지원하는 메서드를 4개까지 동시에 실행할 수 있는데, 그 실행의 주체가 스레드 풀이 된다. 아래 예제를 살펴보자.
const crypto = require("crypto");
const pass = "pass";
const salt = "salt";
const start = Date.now();
crypto.pbkdf2(pass, salt, 1000000, 128, "sha512", () => {
console.log("1:", Date.now() - start);
});
crypto.pbkdf2(pass, salt, 1000000, 128, "sha512", () => {
console.log("2:", Date.now() - start);
});
crypto.pbkdf2(pass, salt, 1000000, 128, "sha512", () => {
console.log("3:", Date.now() - start);
});
crypto.pbkdf2(pass, salt, 1000000, 128, "sha512", () => {
console.log("4:", Date.now() - start);
});
crypto.pbkdf2(pass, salt, 1000000, 128, "sha512", () => {
console.log("5:", Date.now() - start);
});
crypto.pbkdf2(pass, salt, 1000000, 128, "sha512", () => {
console.log("6:", Date.now() - start);
});
crypto.pbkdf2(pass, salt, 1000000, 128, "sha512", () => {
console.log("7:", Date.now() - start);
});
crypto.pbkdf2(pass, salt, 1000000, 128, "sha512", () => {
console.log("8:", Date.now() - start);
});
이 예제를 여러번 실행하면 아래와 같이 실행 순서와 시간이 매번 달라지는 것을 확인할 수 있다. 그리고 4개가 주루룩 찍히고 나머지 4개가 또 주루룩 찍히는 것도 확인할 수 있다.
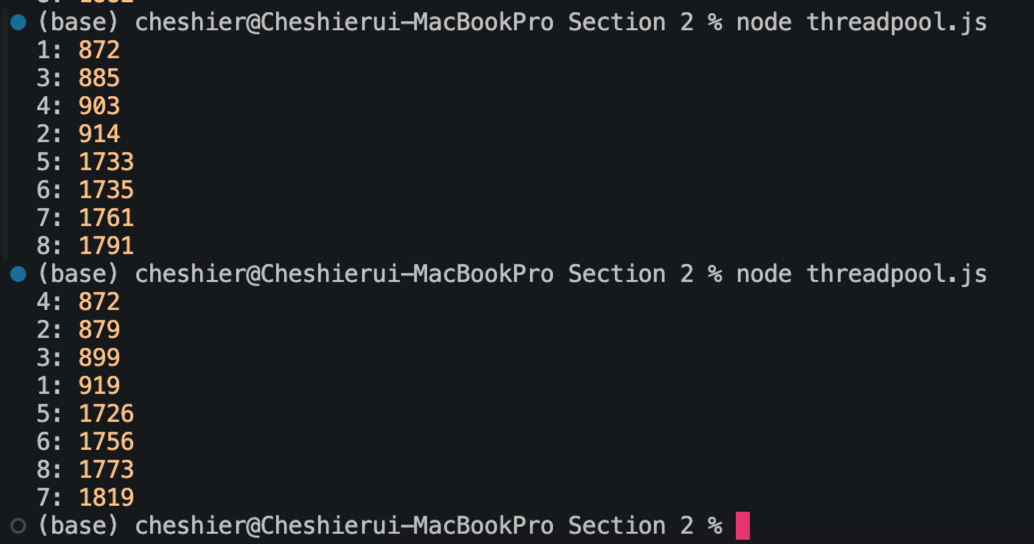
이런 결과가 나오는 이유는 앞서 서술했듯 스레드 풀의 개수가 노드에서 기본으로 설정한 4개이기 때문에 그렇다. 이 스레드 풀은 직접 조작할 수는 없어도, 가동할 스레드 풀의 개수를 조작할 수는 있다. 운영체제에 따라 아래와 같은 명령어를 터미널에 입력하면 된다.
- Windows:
SET UV_THREADPOOL_SIZE=1 - POSIX(Mac, Linux):
UV_THREADPOOL_SIZE=1
위 명령어는 스레드 풀의 개수를 1개로 조작하는 명령어이다. 저렇게 설정하고 위 예제를 다시 돌려보면 비동기적으로 동작하지만 메서드를 실행할 스레드 풀이 한 개 뿐이므로, 순서대로 작업들이 처리됨을 확인할 수 있을 것이다.
다만 스레드 풀의 개수를 높일 때는 실행 환경의 CPU 코어 개수보다 높게 설정하지는 말자.
3.7 이벤트 이해하기
이벤트는 브라우저의 이벤트를 떠올리면 된다. 보통 브라우저에서 많이 일어나는 클릭 이벤트, 호버 이벤트, 키보드 이벤트에 대해 이벤트 리스너와 콜백을 등록해서 코딩했던 것 처럼, 노드에서도 이벤트를 발생시키고 리스너에 콜백을 달아줄 수 있다.
아래 예제를 살펴보자.
const EventEmitter = require("events");
const myEvent = new EventEmitter();
myEvent.addListener("event1", () => {
console.log("이벤트 1");
});
myEvent.on("event2", () => {
console.log("이벤트 2");
});
myEvent.on("event2", () => {
console.log("이벤트 2 추가");
});
myEvent.once("event3", () => {
console.log("이벤트 3");
}); // 한 번만 실행됨
myEvent.emit("event1"); // 이벤트 호출
myEvent.emit("event2"); // 이벤트 호출
myEvent.emit("event3");
myEvent.emit("event3"); // 실행 안 됨
myEvent.on("event4", () => {
console.log("이벤트 4");
});
myEvent.removeAllListeners("event4");
myEvent.emit("event4"); // 실행 안 됨
const listener = () => {
console.log("이벤트 5");
};
myEvent.on("event5", listener);
myEvent.removeListener("event5", listener);
myEvent.emit("event5"); // 실행 안 됨
console.log(myEvent.listenerCount("event2"));
new EventEmitter()는 이벤트를 호출할 수 있는 인스턴스를 반환한다.
이 인스턴스에 대해 아래의 메서드들을 활용할 수 있다.
addListener(eventName, cb)-> 리스너를 등록한다.on(eventName, cb)-> 위와 동일. on은 addListener()의 별칭이다.once(eventName, cb)-> 한번만 실행되는 리스너를 등록한다.emit(eventName)-> 이벤트를 호출한다.removeListener(eventName, listener)-> 해당 이벤트의 리스너를 제거한다.off(eventName, cb)-> 위와 동일. removeListener()의 별칭이다.removeAllListener(eventName)-> 해당 이벤트의 리스너를 모두 제거한다.listenerCount(eventName)-> 해당 이벤트의 리스너 개수를 반환한다.
3.8 예외 처리하기
노드에서는 예외처리가 매우 중요하다. 처리하지 못한 에러가 프로그램 전체를 중단시킬 수도 있고, 싱글 스레드 기반인 노드의 메인 스레드가 중단된다면 복구하지 못하는 데이터의 유실 등 매우 큰 피해를 초래할 수 있기 때문에 예외 처리는 매우 중요한 것이다.
참고로 자바스크립트에서 '예외'란 '처리하지 못한 에러'를 의미하며, 예외나 에러나 동일시되는 것이 일반적이다. 일단 둘 다 처리해줘야하는 대상이기 때문이다.
그러면 에러는 어떻게 처리할까? 기본적인 방법은 try-catch문으로 감싸주는 것이 있다.
setInterval(() => {
console.log("시작");
try {
throw new Error("서버를 고장내주마!");
} catch (err) {
console.error(err);
}
}, 1000);
1초에 한번씩 '시작' 문자열을 출력하는 프로그램에서 만약 저 throw new Error('서버를 고장내주마!');를 try-catch문으로 감싸지 않으면 당연하게도 프로그램이 뻗어버린다.
하지만 저렇게 try-catch문으로 감싸주는 것으로도 프로그램은 콘솔에 에러의 내용을 출력하면서 잘 돌아가게 된다.
하지만 에러가 발생할 여지가 있는 모든 부분에 try-catch문으로 감싸버리면 노드 내부의 에러 처리 기능을 하나도 이용하지 않는 것과 다름 없기에, 또 다른 에러 �처리 방법을 알아보도록 하자.
const fs = require("fs");
setInterval(() => {
fs.unlink("./abcdefg.js", (err) => {
if (err) {
console.error(err);
}
});
}, 1000);
fs 모듈의 unlink() 메서드는 콜백의 인자에 이미 에러 객체가 있고, 내부적으로 처리를 하고 있기 때문에 에러 처리를 해주지 않아도 된다. 대신 로깅을 위해서 해당 에러 객체를 콘솔로 출력하던 파일로 저장하던 하는 로직은 필요할 수 있다.
const fs = require("fs").promises;
setInterval(() => {
fs.unlink("./abcdefg.js").catch(console.error);
}, 1000);
프로미스에서도 .catch()라는 후속 처리 메서드로 에러를 처리해줄 수 있다.
노드 버전 15까지는 catch()를 안 붙여도 노드 프로세스가 중단되지는 않지만 경고가 무진장 많이 뜨기 때문에 웬만하면 붙여주도록 하자.
버전 16부터는 catch()를 안 붙이면 노드 프로세스가 중단된다.
마지막으로 모든 예기치 못한 에러를 처리할 수 있는 방법이 있는데, 이 방법은 콜백의 실행이 보장되지도 않아서 복구 작업용으로 사용하는 것을 지양하고 있고(공식문서 왈), 에러 내용 기록용으로 사용하는 것이 권장되고 있다.
process.on("uncaughtException", (err) => {
console.error("예기치 못한 에러", err);
});
setInterval(() => {
throw new Error("서버를 고장내주마!");
}, 1000);
setTimeout(() => {
console.log("실행됩니다");
}, 2000);
바로 process 객체에 'uncaughtException' 이벤트 리스너를 달아주는 것이다. 이렇게 하면 모든 예외에 대해 리스너가 동작하게 된다. 그래서 만약 나중에 이 리스너에 의해 기록된 에러가 있으면, 추적해서 해당 에러를 따로 처리해주면 된다.
3.8.1 자주 발생하는 에러들
노드에서 자주 발생하는 에러들에 대해서는 알아두면 좋다. 해결 방법은 인터넷에도 나와있고 직접 체득해도 되지만, 해결 방법을 대충이라도 미리 알아두면 해당 에러를 직면했을 때 떠오르는 좋은 힌트가 될 수 있으니 한번 짚고 넘어가보려한다.
node: command not found: 노드는 설치됐지만 환경변수 설정이 안된 경우ReferenceError: module is not defined: 모듈을 require 안했음Error: Cannot find module 'module': 해당 모듈을 require했지만 설치를 안함Error [ERR_MODULE_NOT_FOUND]: 존재하지 않는 모듈을 불러옴Error: Can't set headers after they are sent: 요청에 대한 응답을 두번 보냄FATAL ERROR: CALL_AND_RETRY_LAST Allocation failed- JavaScript heap out of memory: 메모리 부족UnhandledPromiseRejectionWarning: Unhandled promise rejection: 프로미스에 catch 안 붙임EADDRINUSE portnum: 포트번호를 이미 다른 프로세스가 사용 중인 경우EACCES / EPERM: 노드에 권한 부여가 제대로 안된 경우EJSONPARSE: package.json에 문법 오류ECONNREFUSED: 요청을 보냈으나 연결이 성립하지 않았을 때ETARGET: package.json에 기록한 패키지의 버전이 존재하지 않는 경우ETIMEOUT: 요청을 보냈지만 응답이 시간 내에 오지 않은 경우ENOENT : no such file or directory: 지정한 폴더나 파일이 존재하지 않는 경우